A data structure is a specific kind of computer data management, organization, and storage format designed for effective access and modification. For the creation of algorithms and software, they are essential building elements. Arrays, linked lists, stacks, queues, trees, and graphs are examples of common data structures.
Every kind is distinct in its features and applications, suited to certain types of data processing and administration chores. By knowing and using the right data structure, developers may guarantee effective resource use, improve data retrieval speed, and optimize performance within their applications.
What is Data Structure?
An organized and managed data structure allows for effective access and alteration of the data. It provides an efficient way to manage data for different computing tasks and specifies the link between data items. Basic to computer science, data structures are necessary to build effective algorithms.
These include more complicated structures like stacks, queues, trees, and graphs in addition to simpler ones like arrays and linked lists. Speed and scalability of software applications is greatly impacted by data structure used, hence problem-solving and resource optimisation depend heavily on it.
Type of Data Structure
Linear and nonlinear data structures are the two basic categories into which data structures can be generally divided; each has a unique collection of structures designed for certain purposes and needs.
Linear Data Structures
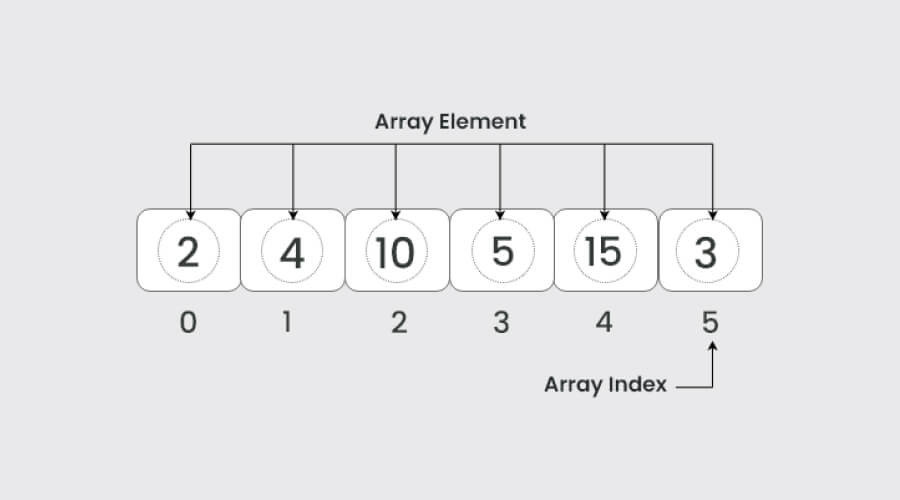
1. Arrays
Image Source – GeeksforGeeks
Arrays are collections of items identifiable by indices kept in adjacent memory regions. They provide easy access to components for circumstances demanding regular retrievals and modifications. Algorithm development and software engineering depend heavily on arrays because they provide effective indexing and quick access to stored data.
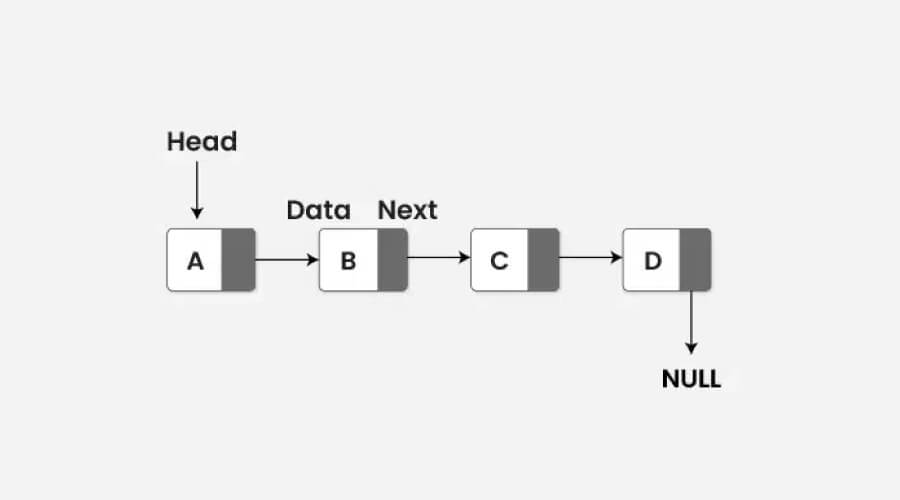
2. Linked List
Image Source – GeeksforGeeks
Linked Lists consist of nodes containing data and a reference to the next node. Their effectiveness with insertions and deletions qualifies them for use in dynamic data management. Linked Lists provide flexibility and effective memory utilization, which are essential for data structures and computer programming and are widely employed in situations where memory allocation and deallocation are frequent.
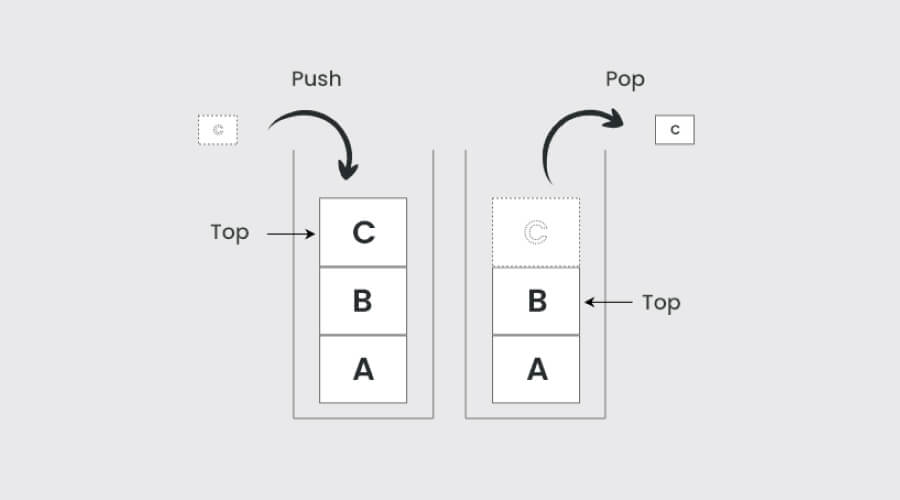
3. Stacks
Image Source – GeeksforGeeks
Last In, First Out (LIFO) is the guiding concept for Stacks. Their effective access to the most recently added components makes them widely employed in function call management, expression evaluation, and parsing. A basic data structure in computer science, Stacks are essential for memory management, recursive function handling, and algorithm implementation.
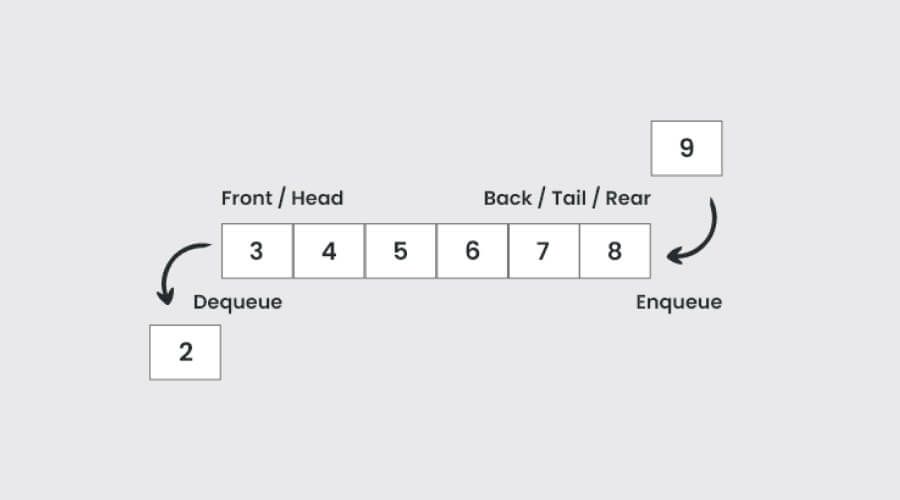
4. Queues
Image Source – GeeksforGeeks
First In, First Out, or FIFO, is the way Queues work. They help to ensure the orderly processing of components by scheduling, buffering, and controlling jobs in resource pools. Widely utilized in real-time processing, networking, and operating systems, Queues make resource allocation and smooth task execution possible, which makes them essential to system architecture and software development.
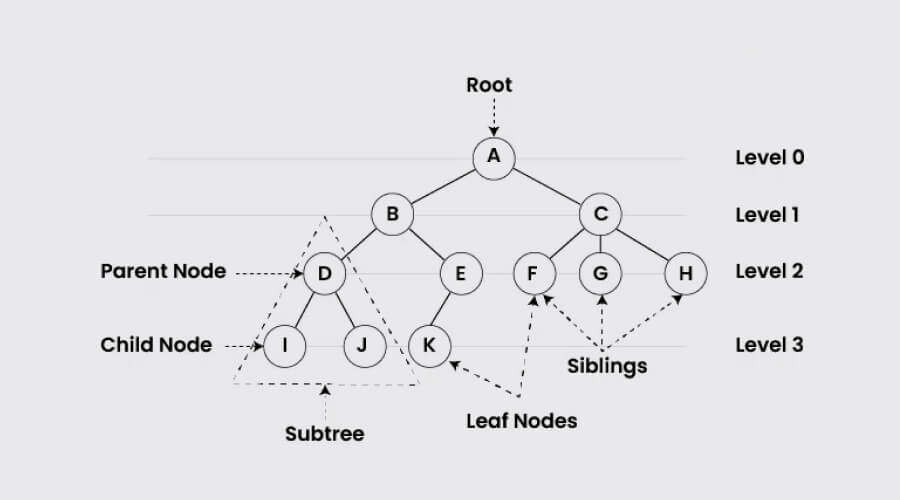
Trees are hierarchical data structures made up of nodes with zero or more child nodes. Hierarchical data may be efficiently searched for, sorted, and represented using variants such as binary trees, AVL trees, and B-trees. Because they provide organized and effective data management and retrieval, Trees are essential to database indexing, file systems, and decision-making algorithms.
2. Graphs
Image Source – GeeksforGeeks
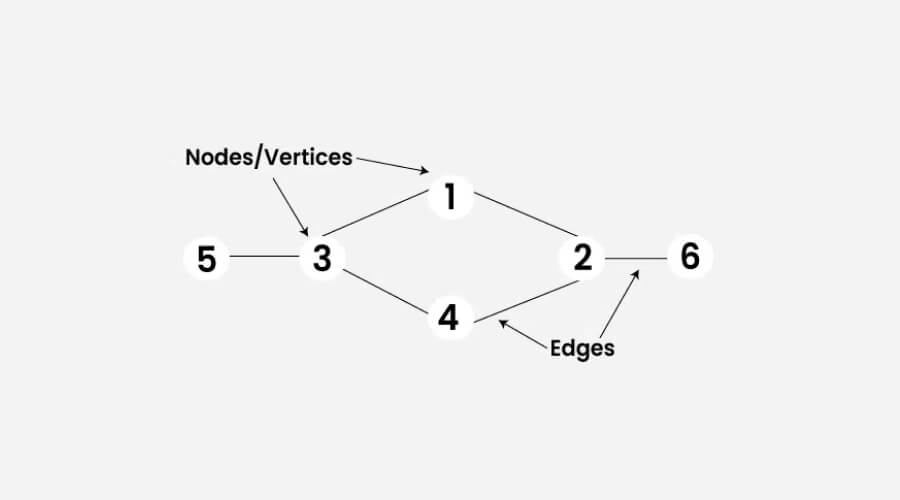
Graphs are data structures of nodes joined by edges representing networks, interactions, and paths. They are necessary to solve connectivity and shortest route issues and may be weighted or not, directed or not. Often employed in dependency resolution, routing algorithms, and social networks, graphs make it easier to represent and examine intricate interactions.
Specialized Data Structures
1. Hash Tables
Image Source – GeeksforGeeks
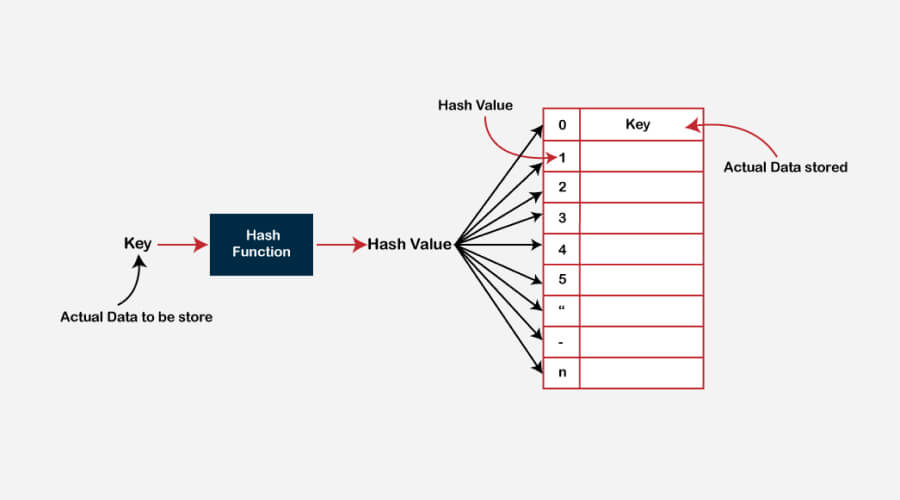
Because Hash Tables store data using key-value pairs, search, insert, and delete operations can be performed quickly and with average-case constant time complexity. Widely employed in applications needing fast lookups, like databases and caches, hash tables effectively handle associative arrays, offering strong performance for a range of computational operations and data management situations.
2. Heaps
Image Source – GeeksforGeeks
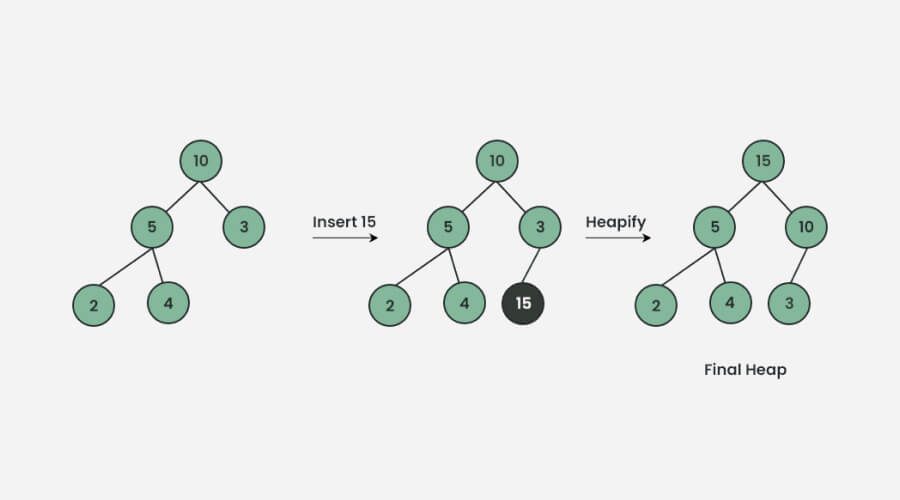
A Heap is a kind of customized tree-based structure in which the parent node is either larger or smaller than its child nodes. Their main applications are in the implementation of heapsort and priority queues. Because Heaps make scheduling, dynamic data processing, and resource allocation ideal, they are essential to computer science applications that depend on performance.
Effective data management and algorithm creation in computer science are based on data structures. From linear structures like arrays and linked lists to nonlinear structures like trees and graphs, they include a range of organizational styles, each suited to specific jobs and performance needs.
The selection of the right data structure affects the general effectiveness and scalability of software programs by improving tasks like sorting, searching, and data retrieval. Developers may use data structures to build strong, responsive systems that can handle a variety of computational problems successfully and efficiently by grasping their properties and applications.
FAQs
Q1. Why are data structures important in computer science and software development?
Data structures are crucial because they effectively manage and organize data in computer memory. Their effects on algorithms’ and applications’ scalability and performance ensure the best possible data retrieval, storage, and manipulation.
Q2. What factors should be considered when choosing a data structure for a specific application?
The kind of operations needed—insertions, deletions, searches—how often they are performed, memory limitations, and the anticipated volume and spread of the data all have a role. Selecting the appropriate data structure may greatly improve the program’s effectiveness and performance.
Q3. How do data structures contribute to algorithm design and optimization?
Data structures affect algorithm design by determining the effectiveness of actions like sorting, searching, and accessing data. Algorithms that use well-selected data structures may process data more rapidly and with less memory, which results in optimized computational problem solutions.
Q4. Which practical instances demonstrate the need to know data structures?
Understanding data structures is essential in disciplines like database administration, web development (e.g., search algorithm optimization), game creation (e.g., pathfinding algorithms), and networking (e.g., routing algorithms). Furthermore, data structures are essential to system architecture and provide effective data storage and retrieval in applications.
Q5. How can proficiency in data structures enhance a developer’s skill set?
Knowing data structures well helps programmers produce more scalable and efficient code, solve performance problems more successfully, and choose the right techniques for challenging situations. It improves problem-solving skills and is necessary for advancement in computer science and software engineering.